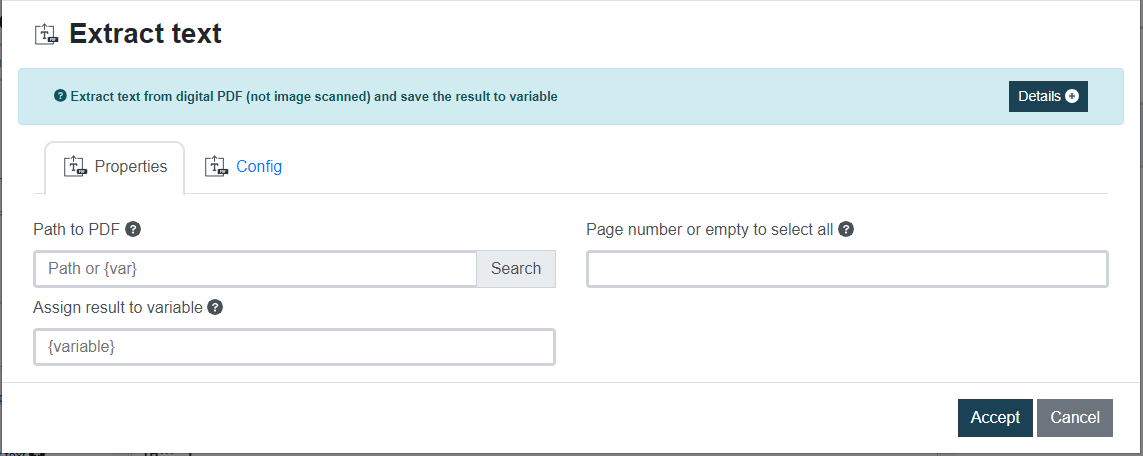
Archivos \ PDF – Extraer texto de PDF
Este comando se utiliza para extraer texto de un archivo PDF digital (no un PDF escaneado de imagen) y guardar el resultado en una variable. El diccionario devuelto le permitirá acceder y manipular el texto extraído para una mayor automatización.
| Datos de entrada | Descripción | Ejemplo |
|---|---|---|
| Archivo PDF | Nombre y ruta del archivo PDF del que desea extraer texto. | C:/Users/pc/Desktop/file.pdf |
| Página o vacío para buscar todos | Puede especificar el número de página del que desea extraer el texto. Si desea extraer texto de todas las páginas, deje este parámetro vacío. | |
| Asignar resultado a variable | Nombre de la variable Rocketbot donde se guardará el texto extraído. | {var} |
Imagen de ejemplo